如何使用檢視器除錯辨識
簡介
Tesseract 具有內建顯示其內部狀態的功能,因此您可以檢視其分段和辨識結果。
建置與安裝
執行檢視器需要下列元件
- Java 執行階段
- piccolo2d-core-3.0.jar
- piccolo2d-extras-3.0.jar
- jaxb-api-2.3.1.jar
ScrollView.jar,從 tesseract/java 中的原始碼建置,或下載 ScrollView.jar(在 64 位元 Linux 上使用 jaxb-api-2.3.1.jar、piccolo2d-core-3.0.jar、piccolo2d-extras-3.0.jar 和 javac 1.8.0_181.md 建置)
如果您的路徑中有 curl,make ScrollView.jar 會將它們自動下載到 tesseract/java。
所有這些 jar 檔案都需要放在單一目錄中。Tesseract 會透過環境變數 SCROLLVIEW_PATH 或具有相同名稱的編譯器定義來得知位置。
Dmitri Silaev 提供的替代下載連結位於 http://www.4shared.com/zip/FnP8RSu0/tess_debug_3_02.html。將下載的封包中的 piccolo-1.2.jar、piccolox-1.2.jar 和 ScrollView.jar 複製到 C:\Tesseract-OCR\java。
在 Linux 上
- 將 piccolo2d-core-3.0.jar、piccolo2d-extras-3.0.jar 和 jaxb-api-2.3.1.jar 複製到 tesseract/java。
- cd java
make ScrollView.jar- 設定 SCROLLVIEW_PATH 環境變數,使其指向包含所有 3 個 jar 檔案的 java 目錄。
在 Windows 上
未定義建置 ScrollView.jar 的建置程序。它包含在 tesseract-2.04.exe.tar.gz、tesseract-ocr-3.02-win32-portable.zip 和 tesseract-ocr-setup-3.02.02.exe 封包中。將 piccolo-1.2.jar 和 piccolox-1.2.jar 放在相同位置 (Tesseract-OCR/java)。然後設定 SCROLLVIEW_PATH 環境變數,使其指向 java 目錄。
分段器除錯模式
若要執行分段器測試,請嘗試以下操作
tesseract phototest.tif test1 segdemo inter
您應該會看到類似這樣的內容
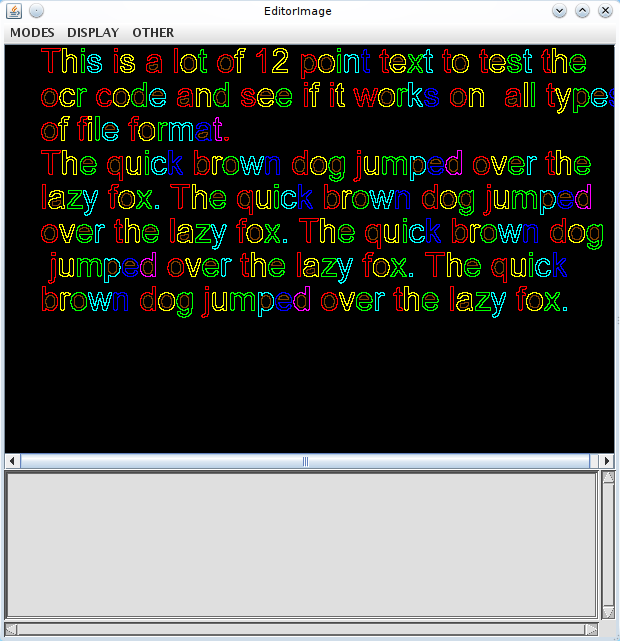
影像中找到的文字會以藍色矩形表示。有 3 個選單
「模式 (MODES)」設定左鍵單擊或選取操作的模式。「顯示 (DISPLAY)」變更視窗的請求顯示內容。(不會立即變更)「其他 (OTHER)」提供許多其他雜項全域動作。如果您在「編輯器影像」視窗中按一下滑鼠右鍵,您可以動態變更任何「新」設定變數的值。不過,根據您想要變更的內容,許多有用的變數都是舊樣式,無法透過這種方式變更。有一天,會有人將所有舊樣式變數更新為新樣式變數。
請注意,選單看起來相當奇怪。這是因為該工具最初設計的目的是提供建立精確度極高的 ground truth 檔案的功能,其中包含字元標籤、組成每個字元的已連結元件的相關資訊等。此功能的大部分都是多餘的,而且 10 多年來未使用過。某些宣傳的功能可能會輕易導致程式當機,但此處記載的功能應該可以運作…
若要顯示字元,請取消選取「顯示/邊界框 (DISPLAY/Bounding Boxes)」,選取「顯示/多邊形近似 (DISPLAY/Polygonal Approx)」,然後選取「其他/統一顯示 (OTHER/Uniform display)」。
若要放大,請將游標放在文字上方,然後將滑鼠滾輪朝遠離您的方向滾動 2 或 3 下。每次單擊都會將大小加倍。若要縮小,請將滑鼠滾輪朝您的方向滾動。如果您沒有滑鼠滾輪…您可能運氣不佳。Java 程式碼在這方面需要進行一些調整。
現在選取「模式/辨識文字 (MODES/Recog words)」,然後按一下文字。如果您選擇文字「code」(第二行的第二個文字),則您應該會得到類似這樣的內容
您也可能會在您啟動 tesseract 的終端機視窗中看到文字
chop_word:
6.81 -2.16 : c [63 ]a 14.38 -4.56 : o [6f ]a 14.53 -4.61 : e [65 ]a 15.15 -4.81
: ¢ [a2 ]
chop_word:
3.98 -1.11 : 0 [30 ]0 8.37 -2.33 : o [6f ]a 10.94 -3.04 : c [63 ]a 14.43 -4.01 :
¤ [a4 ]
chop_word:
8.24 -1.77 : d [64 ]a
chop_word:
17.58 -4.26 : e [65 ]a 23.65 -5.73 : a [61 ]a
system words:
52.17 -5.73 : c [63 ]a : o [6f ]a : d [64 ]a : a [61 ]a 45.49 -4.26 : c [63 ]
a : o [6f ]a : d [64 ]a : e [65 ]a
permute_characters : 45.49 -4.26 : c [63 ]a : o [6f ]a : d [64 ]a : e [65 ]a
system words:
52.17 -5.73 : c [63 ]a : o [6f ]a : d [64 ]a : a [61 ]a 45.49 -4.26 : c [63 ]
a : o [6f ]a : d [64 ]a : e [65 ]a
permute_characters : 45.49 -4.26 : c [63 ]a : o [6f ]a : d [64 ]a : e [65 ]a
這一切的含義:在每個 chop_word: 後面的行是每個原始已連結元件的分類器輸出,如「編輯器影像」視窗中以不同顏色顯示的。每個分類器結果都包含一個評分、一個信賴度、一個字串、其十六進位 Unicode 表示法,以及一個表示其 ctype 的字元。評分是一個正距離數字,並根據外框長度進行縮放。信賴度是距離最近原型之間的距離,但會取負數,因此負數越大表示越差,而越接近零的數字表示越好。ctype 是「a」(小寫字母)、「A」(大寫字母)、「x」(兩者都不是的字母)和「0」(數字)。沒有 ctype 表示以上皆非。
最後一個 chop_word 後面是 permute_characters。這會顯示從分類器輸出建立字串的第一次嘗試。評分是所有字元評分的總和,而信賴度是所有字元中最差的。
在這種情況下沒有,但 improve 1 和 improve 2 會是已切分的 blob 的 2 個一半,以及對應的 permute_characters。
現在按一下「分段」視窗。您會看到 d 和 e 都變成同一種顏色,並且對應的分類器結果會出現在您的終端機上。這是相關器在實驗不同的字元分段,以查看是否可以改善結果。
再次按一下,它會實驗合併 c 和 o,然後是 o 和 d,最後是同時合併 c 和 o 以及 d 和 e。
再按一下,您會看到一個名為 FXDemo 的新視窗,顯示文字的最終分段,其中包含基線和平均線。
您現在可以回到編輯器視窗中按一下。由於 tesseract 不是可重入的,因此您一次無法辨識一個以上的文字,因此當分段器正在執行時,您無法啟動另一個;-)
分類器除錯模式
tesseract phototest.tif test1 matdemo inter
與 segdemo 相同,若要顯示字元,請取消選取「顯示/邊界框 (DISPLAY/Bounding Boxes)」,選取「顯示/多邊形近似 (DISPLAY/Polygonal Approx)」,然後選取「其他/統一顯示 (OTHER/Uniform display)」。
現在選取「模式/辨識 blob (MODES/Recog blobs)」,然後按一下字元。如果您選擇文字「code」中的字元「e」(第二行的第二個文字),則您應該會得到類似這樣的內容(您可能需要捲動視窗才能讓字元位於中心)
並且此文字應該會出現在您的終端機中
AD Matches = e [65 ]a(8) 21.83 a [61 ]a(16) 29.38
Debugging class = e (All Templates) ...
Best built-in template match is config 24 (21.0) (cn=0)
No AD templates for class 8 = e
Integer Matcher -------------------------------------------
Match Complete --------------------------------------------
Left-click in IntegerMatch Window to continue or right click to debug...
現在,如果您按一下滑鼠右鍵,您會看到一個小的快顯選單,其中包含 3 個項目。理論上,您可以要求它使用自適應、靜態或兩組範本來進行除錯。程式碼尚未編寫來區分不同的選單項目,而且即使編寫了,也不會產生任何影響,因為其餘程式碼保持不變。您沒有自適應範本,因為 pass1 尚未執行。在某個時間點,這將會修正,讓您可以選擇觀察在 pass1 或 pass2 中處理文字的方式。屆時才有意義。
因此,請按一下隨機選單項目,您會看到一個對話方塊文字方塊,要求您輸入要除錯的類別。它要求字元類別的字串,對於大多數拉丁語言來說,它只是一個字元,但對於其他語言(例如卡納達語)來說,它可能是一連串字元。為了讓非語言使用者更容易輸入非鍵盤字元,此方塊接受 0xdddd 作為 4 位數的十六進位 Unicode 碼。
這次輸入一個小寫 c,然後按一下 Enter(按一下「確定」似乎無法運作!),您應該會在終端機視窗中看到以下內容
Debugging class = 34 = c (All Templates) ...
Best built-in template match is config 4 (22.0) (cn=1)
No AD templates for class 34 = c
Integer Matcher -------------------------------------------
Match Complete --------------------------------------------
Left-click in IntegerMatch Window to continue or right click to debug...
IntMatchWindow 應該會顯示小寫 c 非常匹配。事實上,它獲得一個介於上述 e 和 a 之間的數字,表示 c 已被類別修剪器拒絕。
在 IntMatchWindow 中,會顯示特徵和原型之間的對應關係。原型是細長的線條,而特徵是較短較粗的線條。從最佳匹配到最差匹配的顏色,會依循這個稍微隨意的順序:白色、綠色、紅色、藍色。灰線應該表示未知項目所匹配的原型類型,但它們似乎落後一個分類。正方形表示靜態分類器,並顯示正規化單位。軌道線表示自適應分類,並顯示基線、平均線、下降線和上升線的位置。
其他「模式 (MODE)」的可能性
一般而言,選取的「模式 (MODE)」將對您使用滑鼠左鍵選取或按一下的 blob 或文字執行一些動作。
「模式 (MODE)」中的「顯示 BL 正規化文字 (Show BL Norm Word)」會在獨立視窗中顯示您按一下的文字(在編輯器視窗中),並加上基線和平均線。在撰寫本文時,您必須將滑鼠移至 BlnWords 視窗上方,才能顯示任何內容。
「辨識 blob (Recog Blobs)」對於在單一 blob 上測試分類器非常有用,而無需按一下所有分段。它會將選取範圍視為「文字」,因此您可以選取一個以上的 blob,並有機會看到大部分已分類的組合。
「顯示點 (Show point)」對於取得 tesseract 座標空間中特定 blob 的座標非常有用,因此您可以將它們輸入 textord_test_x 和 textord_test_y,以找出為何某些特定 blob 從未出現在輸出中。
只有其他少數「模式 (MODEs)」會執行任何動作,包括「傾印文字 (Dump Word)」、「行間距直方圖 (Row Gaps Hist)」和「區塊間距直方圖 (Block Gaps Hist)」,所有這些都會將資訊傾印到您的終端機視窗。
其他「顯示 (Display)」模式
您可以藉由不選取「顯示/邊界框 (Display/Bounding Boxes)」並選取「顯示/多邊形近似 (Display/Polygonal Approx)」後,不選取「其他/統一顯示 (Other/Uniform Display)」,來節省一些顯示時間。相反地,您按一下的每個文字都會以新格式重新顯示
疑難排解
在大量 ScrollView: 等待伺服器… 訊息的中間收到「kill %1: no such job」訊息?您在啟動 Java 時遇到問題。在 Windows 上,錯誤訊息應該會傳送到您的終端機視窗,但在 Linux 上,您必須編輯 svutil.cpp,才能從 cmd_template 字串中移除「>/dev/null 2>&1」。
嘗試在 Linux 上執行此命令
java -Xms512m -Xmx1024m -Djava.library.path=$SCROLLVIEW_PATH -cp $SCROLLVIEW_PATH/ScrollView.jar:$SCROLLVIEW_PATH/piccolo-1.2.jar:$SCROLLVIEW_PATH/piccolox-1.2.jar com.google.scrollview.ScrollView
在 Windows 上嘗試執行此命令
java -Xms512m -Xmx1024m -Djava.library.path=%SCROLLVIEW_PATH% -cp %SCROLLVIEW_PATH%/ScrollView.jar;%SCROLLVIEW_PATH%/piccolo-1.2.jar;%SCROLLVIEW_PATH%/piccolox-1.2.jar com.google.scrollview.ScrollView
如果 java 和 SCROLLVIEW_PATH 設定一切正常,您應該會看到
Socket 已在連接埠 8461 上啟動。
否則您需要修正問題,例如:
- 未安裝 Java 執行環境
- Java 不在路徑中
- SCROLLVIEW_PATH 包含空格或非 ASCII 字元
其他您應該知道的事項
這是一個除錯工具,不是一個正式的 UI,因此,它無法很好地處理正常執行路徑以外的任何情況。問題/錯誤包括但不限於:
- 如果您關閉其中一個次要視窗,則必須重新啟動 tesseract 才能使其再次出現。
- Java 檢視器程序現在大多時候都能正確終止。如果當您期望檢視器出現時,Tesseract 似乎掛起,則很可能是因為您有一個必須手動終止的流氓 Java 程序。
- 您仍然無法同時使用新的檢視器執行多個 Tesseract。
- 此處顯示的示範模式並不能完全重現 Tesseract 中發生的情況,因為未重現 2-pass 性質和自適應分類器。