提升輸出品質
您可能無法從 Tesseract 獲得良好品質輸出的原因有很多。請務必注意,除非您使用的是非常不尋常的字型或新的語言,否則重新訓練 Tesseract 不太可能有所幫助。
影像處理
Tesseract 在執行實際 OCR 之前,會在內部執行各種影像處理操作(使用 Leptonica 函式庫)。它通常在這方面做得很好,但不可避免地會有不夠好的情況,這可能會導致準確性大幅降低。
您可以透過將 設定變數 tessedit_write_images 設定為 true(或在執行 Tesseract 時使用設定檔 get.images),來查看 Tesseract 如何處理影像。如果產生的 tessinput.tif 檔案看起來有問題,請嘗試在將影像傳遞給 Tesseract 之前執行這些影像處理操作。
反轉影像
雖然 tesseract 3.05 版(和更舊的版本)可以毫無問題地處理反轉影像(深色背景和淺色文字),但對於 4.x 版,請使用淺色背景上的深色文字。
重新縮放
Tesseract 在 DPI 至少為 300 dpi 的影像上效果最佳,因此調整影像大小可能會有所幫助。如需更多資訊,請參閱常見問題解答。
“Willus Dotkom” 對最佳影像解析度進行了有趣的測試,並提出了以像素為單位的大寫字母的最佳高度建議。
二值化

這會將影像轉換為黑白。Tesseract 會在內部執行此操作(Otsu 演算法),但結果可能不是最佳的,特別是當頁面背景的深淺度不均勻時。
Tesseract 5.0.0 新增了兩種基於 Leptonica 的二值化方法:自適應 Otsu 和 Sauvola。使用 tesseract --print-parameters | grep thresholding_ 來查看相關的可設定參數。
如果您無法透過提供更好的輸入影像來解決此問題,您可以嘗試不同的演算法。請參閱ImageJ 自動閾值 (java) 或OpenCV 影像閾值處理 (python) 或scikit-image 閾值處理文件 (python)。
雜訊移除

雜訊是影像中亮度或顏色的隨機變化,這會使影像的文字更難以閱讀。某些類型的雜訊無法由 Tesseract 在二值化步驟中移除,這可能會導致準確度下降。
擴張和侵蝕
粗體字元或細體字元(尤其是具有襯線的字元)可能會影響細節的辨識並降低辨識準確度。許多影像處理程式允許對一般背景的字元邊緣進行擴張和侵蝕,以擴張或增大尺寸(擴張)或縮小尺寸(侵蝕)。
可以使用侵蝕技術來補償歷史文檔中的嚴重墨水暈染。侵蝕可以用來將字元縮回到其正常的字形結構。
例如,GIMP 的值傳播濾鏡可以透過降低下限值來產生額外粗體歷史字型的侵蝕。
原始
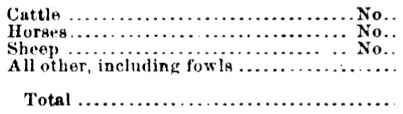
套用侵蝕
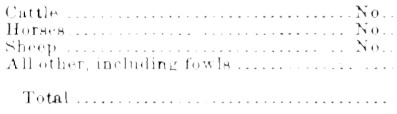
旋轉/傾斜校正

當頁面掃描時未對齊時,就會出現傾斜影像。如果頁面過於傾斜,Tesseract 的行分割品質會顯著降低,這會嚴重影響 OCR 的品質。要解決此問題,請旋轉頁面影像,使文字行水平。
邊框
遺失邊框
如果您僅 OCR 文字區域而沒有任何邊框,tesseract 可能會出現問題。有關詳細資訊,請參閱tesseract 使用者論壇#427。您可以使用ImageMagick® 輕鬆新增小邊框(例如,10 像素)。
convert 427-1.jpg -bordercolor White -border 10x10 427-1b.jpg
過大的邊框
大邊框(尤其是在大型背景上處理單個字母/數字或一個單字時)可能會導致問題(「空白頁面」)。請嘗試將輸入影像裁剪到具有合理邊框(例如,10 像素)的文字區域。
掃描邊框移除

掃描的頁面周圍通常會有深色邊框。這些可能會被錯誤地當作額外的字元拾取,特別是當它們的形狀和漸層變化時。
透明度/Alpha 通道
某些影像格式(例如,png)可以具有alpha 通道來提供透明度功能。
Tesseract 3.0x 希望使用者在使用 tesseract 中的影像之前,從影像中移除 alpha 通道。例如,可以使用 ImageMagick 命令來完成此操作
convert input.png -alpha off output.png
Tesseract 4.00 使用 leptonica 函式 pixRemoveAlpha() 移除 alpha 通道:它會將 alpha 元件與白色背景混合來移除它。在某些情況下(例如,OCR 電影字幕),這可能會導致問題,因此使用者需要自行移除 alpha 通道(或透過反轉影像顏色來預先處理影像)。
工具/函式庫
- Leptonica
- OpenCV
- ScanTailor Advanced
- ImageMagick
- unpaper
- ImageJ
- Gimp
- PRLib - 具有改善 OCR 品質演算法的預辨識函式庫
範例
如果您需要如何以程式方式改善影像品質的範例,請查看此範例
- OpenCV - 旋轉(傾斜校正) - c++ 範例
- Fred 的 ImageMagick TEXTCLEANER - 用於處理掃描的文字文件以清除文字背景的 bash 腳本。
- rotation_spacing.py - 用於自動偵測文字影像的旋轉和行距的 python 腳本
- crop_morphology.py - 使用 Python、OpenCV 和 numpy 在影像中尋找文字區塊
- 使用 OpenCV 和 Python 的信用卡 OCR
- noteshrink - 如何清除掃描的 python 範例。詳細資訊請參閱部落格壓縮和增強手寫筆記。
- unproject text - 如何恢復影像透視的 python 範例。詳細資訊請參閱部落格使用橢圓投射文字。
- page_dewarp - 使用「立方體」模型進行文字頁面去扭曲的 python 範例。詳細資訊請參閱部落格頁面去扭曲。
- 如何使用 OpenCV 從掃描影像中移除陰影
頁面分割方法
依預設,Tesseract 會在分割影像時預期會有文字頁面。如果您只是想 OCR 小區域,請使用不同的分割模式,使用 --psm 引數。請注意,在過於緊密裁剪的文字中新增白色邊框也可能會有所幫助,請參閱問題 398。
若要查看支援的頁面分割模式的完整列表,請使用 tesseract -h。以下是截至 3.21 的列表
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
字典、字詞列表和模式
依預設,Tesseract 已針對辨識單字句子進行最佳化。如果您嘗試辨識其他內容,例如收據、價目表或程式碼,您可以執行一些操作來提高結果的準確性,以及仔細檢查是否已選取適當的分割方法。
如果您的大部分文字不是字典單字,則停用 Tesseract 使用的字典應該會提高辨識度。可以透過將設定變數 load_system_dawg 和 load_freq_dawg 都設定為 false 來停用它們。
也可以將單字新增至 Tesseract 用於協助辨識的單字列表,或新增常見的字元模式,如果您對您預期的輸入類型有很好的了解,這可以進一步幫助提高準確性。這在Tesseract 手冊中有更詳細的說明。
如果您知道您只會遇到語言中可用字元的子集(例如,只有數字),您可以使用 tessedit_char_whitelist 設定變數。請參閱常見問題解答中的範例。
表格辨識
眾所周知,tesseract 無法在沒有自訂分割/版面配置分析的情況下辨識表格中的文字/資料(請參閱問題追蹤器)。您可以嘗試使用/測試Sintun 建議,或從使用 PyTesseract 和 OpenCV 從表格影像中擷取文字/用於文字擷取表格影像的程式碼 中獲得一些想法
仍然有問題嗎?
如果您嘗試了以上所有方法,但仍獲得較低的準確度結果,請在論壇上提問以尋求協助,最好是張貼範例影像。